Govern LLMs · OpenAI-compatible · Native API & SDK
LLM governance to cut cost, optimize usage, and secure every model call at scale
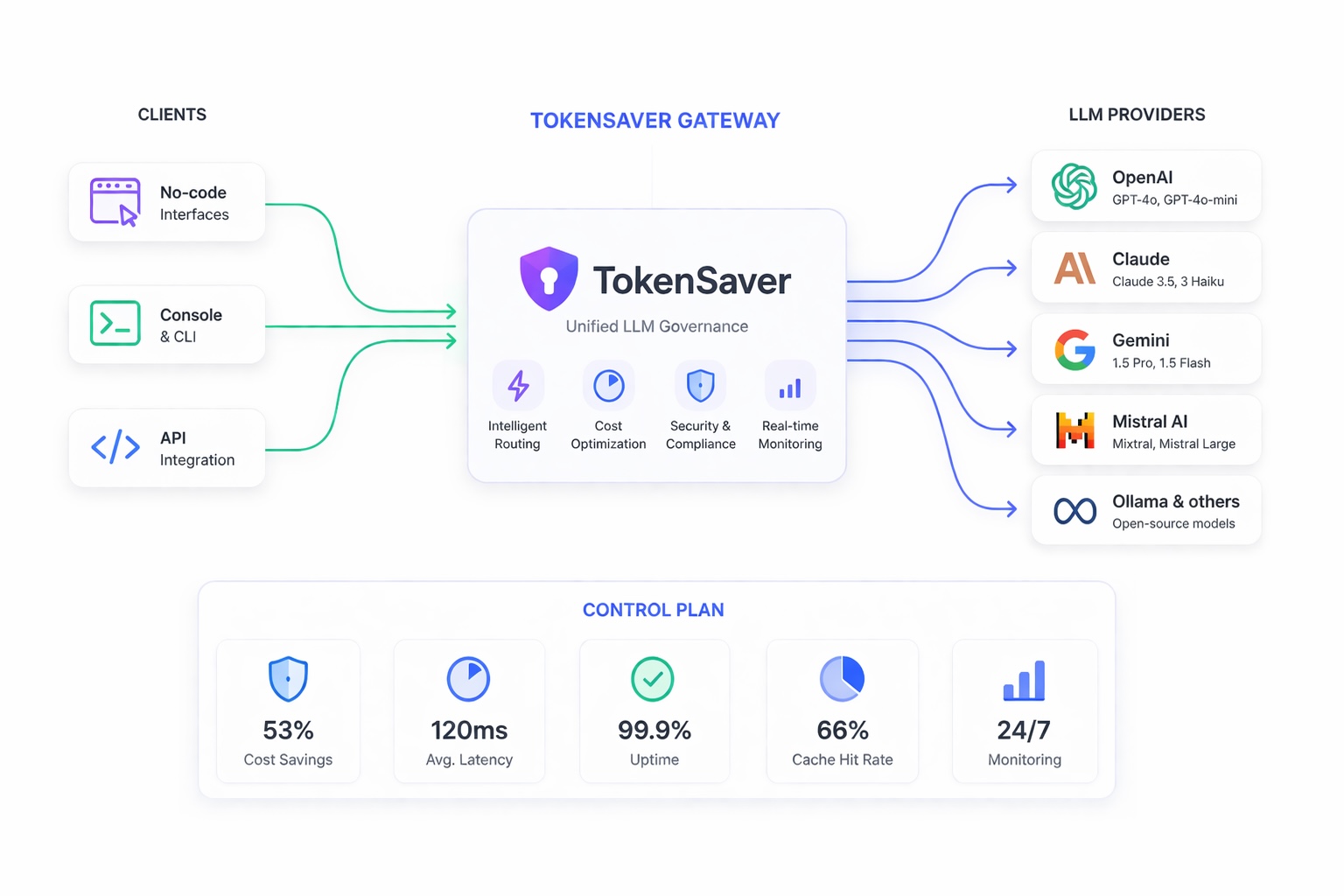
TokenSaver is the control plane for all your LLM traffic: enforce policies, access, and budgets; shrink token bills with semantic cache, RAG, and compression; and keep data safe with PII controls — in one predictable pipeline with full observability. Use the web console, point OpenAI-compatible clients at TokenSaver, or integrate with the native HTTP API and Python SDK— same pipeline, metering, and policies on every path.
Early Adopter Program — free plan to explore governed LLM at scale · One proxy · RAG, cache, and anonymization modules · Policies & spend controls · Works with OpenAI, Anthropic, Google, and more · Open-source Python SDK on PyPI (free for the community)
Early Adopter Program: request free access to discover TokenSaver — your feedback helps steer the product roadmap.