LLM governance · OpenAI-compatible · One control plane
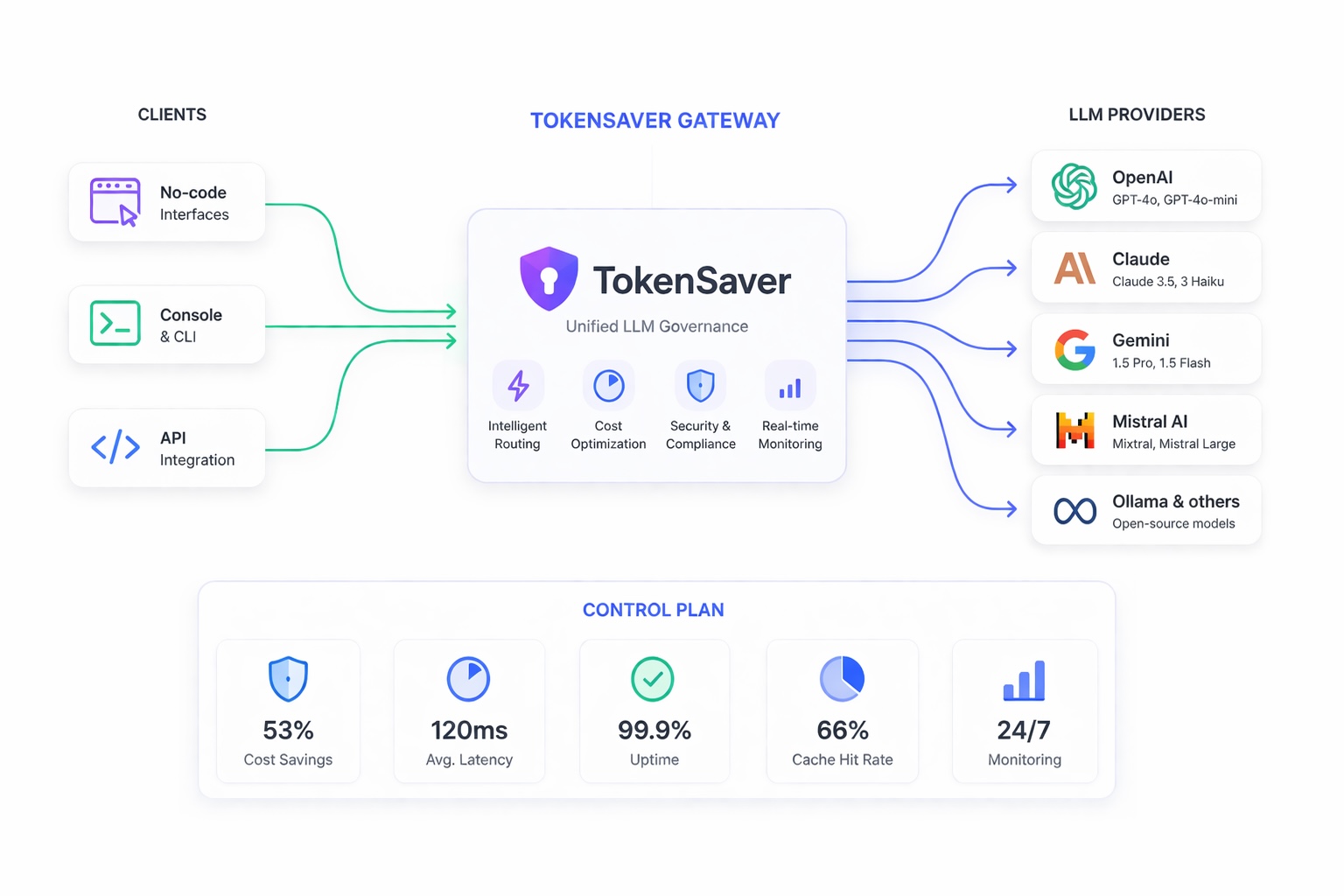
The control plane for governed LLM traffic
Cut token spend, enforce policies, and secure every model call — cache, RAG, compression, and PII in one predictable pipeline with full observability. Console, OpenAI-compatible clients, or native API & SDK — same metering and quotas on every path.
Early Adopter Program— 30-day platform trial (cache, RAG, hosted LLMs) ·Plans from €0 to Enterprise · Open-source Python SDK on PyPI
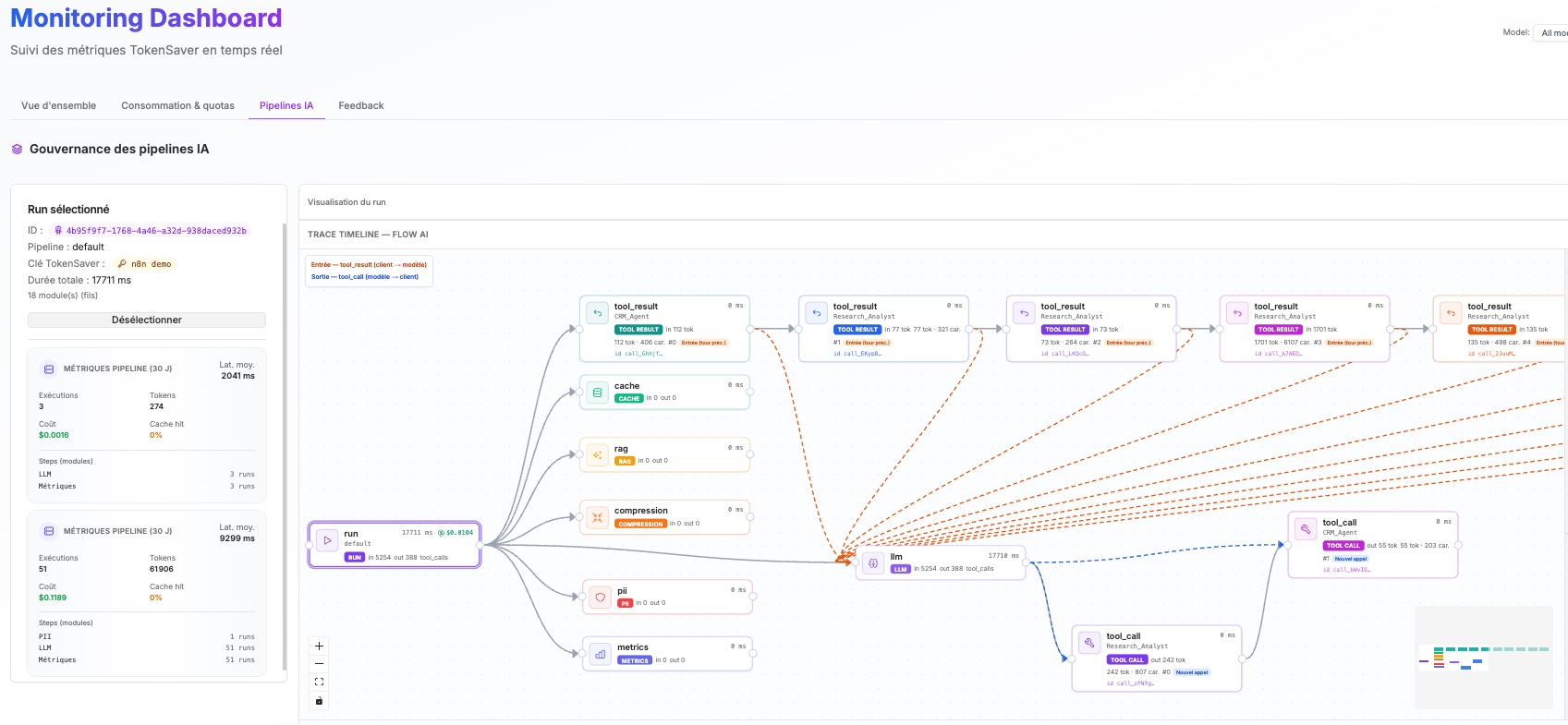
Agentic AI observability
Control and trace cascading agent AI workflows
From a single prompt to multi-step agents calling tools — and agents delegating to other agents — TokenSaver secures and records every exchange. See the full run graph: cache, RAG, compression, PII, LLM calls, and tool results in one trace timeline, with cost, latency, and policy outcomes per step.
- End-to-end visibility on agentic architectures — orchestrators, sub-agents, and tool-assisted runs in one dashboard
- Governance on every hop: org-scoped keys, quotas, PII controls, and audit-ready metrics — not just the final model reply
- Stack-agnostic: route any client through the same governed pipeline — code-first or low-code / no-code
Works with your stack
Why TokenSaver
Less spend, stronger governance, faster shipping
One predictable pipeline in front of every model — semantic cache and RAG cut tokens, PII policies protect data, and observability keeps platform teams in control.
Cut LLM spend
Semantic cache, local RAG, and context compression reduce billed tokens on repeat and document-heavy workflows — tracked per run in the console.
Govern every model
Org-scoped keys, quotas, and a live catalogue — console, OpenAI-compatible clients, or native API, same policies on every path.
Ship agents with confidence
Trace multi-step agent runs end to end: cache, RAG, tools, and model hops with cost and policy outcomes — stack-agnostic from LangChain to n8n.
- 7+LLM providers
- 261+Models in catalogue
- 1Pipeline — cache, RAG, compression, PII, then model
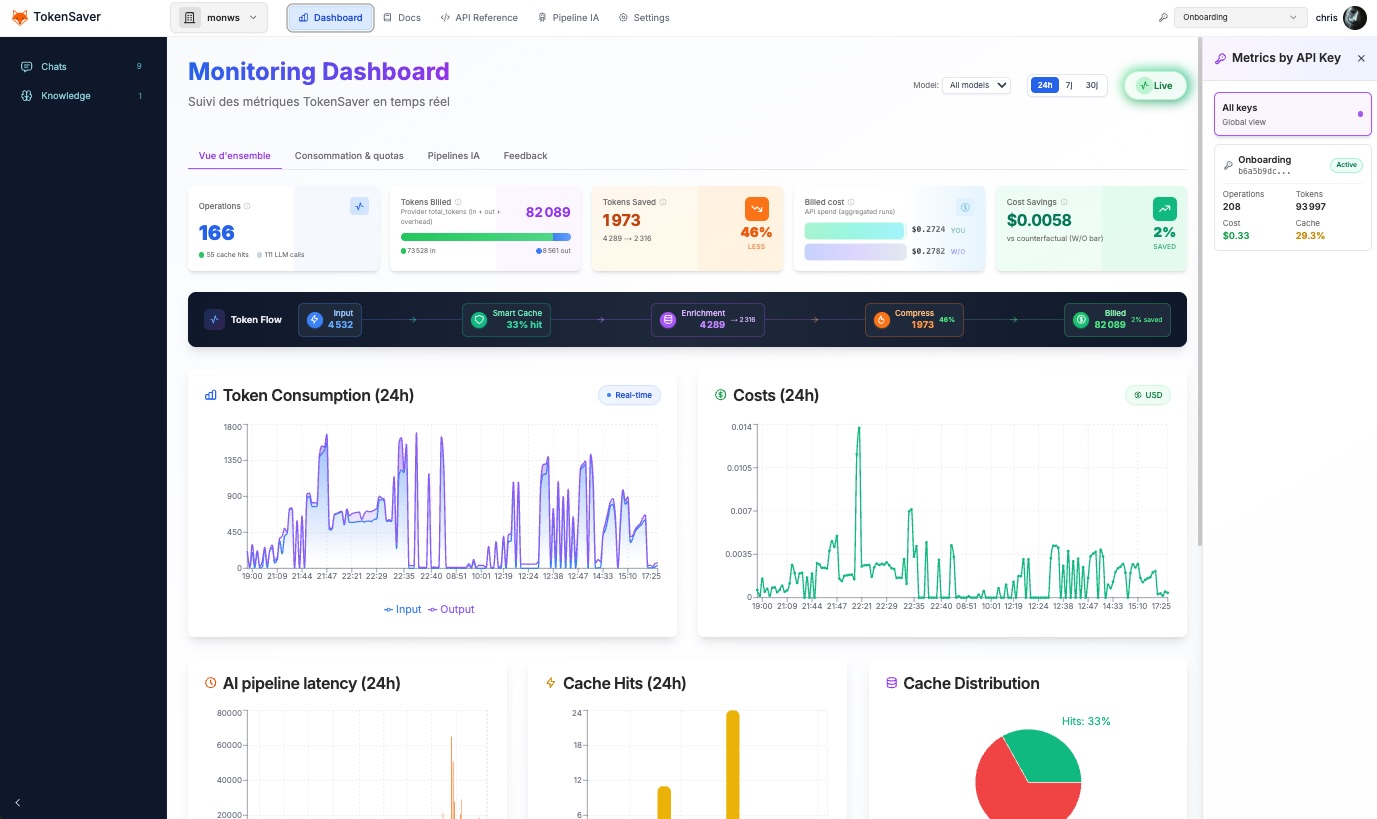
Measured in the console
Lower billed tokens: local RAG, semantic cache, and context compression
Your knowledge base stays in your perimeter. The pipeline runs cache → RAG retrieval → compression of retrieved context → PII anonymization → LLM. Early adopter pilots see measurable savings on repeated prompts and document-heavy flows — tokens saved per run in the dashboard.
The 3 levers tracked in the console
These are not marketing projections: they are TokenSaver modules measured in your dashboard.
- 1 · Semantic cachePilots: 25–45% fewer tokens
When a similar request was already handled, the answer is served again without calling the LLM — you pay few or no tokens on that run.
- 2 · Local RAG + compressionLeaner context in the prompt
Your documents stay in your perimeter; only useful excerpts go to the model, often compressed (Growth) to cut input tokens.
- 3 · Per-run trackingFull cache hit ≈ 0 LLM tokens billed
Every pipeline run shows billed vs saved tokens — use this to measure real ROI on your workflows.
Ballpark figures from early adopter pilots — your real numbers are in the console (tokens saved per run).
View plansGetting started
From API key to governed production traffic
Three steps — details, integrations, and architecture on the Platform page.
Get your TokenSaver API key
Sign in, pick hosted models on Free or attach BYOK on paid plans. Applications call TokenSaver — not scattered vendor keys on app servers.
Set pipeline defaults once
Tune cache, RAG, compression, and PII in the console. The same order runs on console chat, OpenAI-compatible UIs, and the native API.
Monitor spend and policy outcomes
Per-run tokens saved, cache hits, and traces — so product, platform, and finance share one source of truth as usage grows.
Frequently asked questions
What is an LLM gateway?
A single API and policy layer in front of multiple model providers. Your apps call TokenSaver; TokenSaver applies cache, retrieval, compression, and safety, then calls the right model with your org's keys.
Can I use LibreChat or Open WebUI?
Yes — point the OpenAI base URL at TokenSaver's /openai/v1 path and use your TokenSaver API key. Same governed pipeline as the console and native API.
Is the pipeline order fixed?
Yes — cache, RAG, compression, PII, then LLM, then metrics. That predictability keeps debugging and compliance reviews straightforward.
How does TokenSaver optimize tokens and secure prompts?
TokenSaver runs an ordered pipeline: semantic cache, retrieval on your local RAG, compression of injected context, then sensitive-data detection and anonymization (PII) before the LLM call. You cut billed tokens while controlling personal and confidential data sent to models. Same behavior via console, native API, or OpenAI-compatible path — with quotas and monitoring. See plans on Pricing.